
Churn rate. It's probably the most important usage number you could have, but boy is it a pain in the butt to calculate. Or is it?
For ForceRank.it we don't have a ton of traffic so we've still got a simple table of events, where event is something like "login" or "pageview". Whatever your database though I think it's likely you have a table that can function like the following:
So what are the steps we need to do to calculate monthly churn?
1) Figure out how many people used the application each month.
2) For each month, figure out how many of those people did or didn't use it the next month.
So step 1 is trivial, right?
That was easy... but now we're in trouble. We've got the number of active users, but we've lost who they were, so now we can't compare to the next month.
At this point it's easy to end up trying
- Join the table to itself, which is described here but this can get impossibly slow as they explain here.
- Say to hell with it and solve for one month at a time and put that in a cron job, and save it to a new table.
The Problem with Cron
The cron job works, but the sad thing about it is that now we've got a table of churn numbers, but we're locked in and can no longer segment. How do paid users retain vs free users? Sorry, you're going to need to refactor this whole solution.
Enter Window Functions
So is there any way to do this in one fell sql-swoop? The good news is that there is, brought to you by window functions and lag() lead() functions in particular. .
Lag & Lead mean that we can iterate over results, comparing our current row to the next row. This is huge, particularly because we can partition by user. Lag and lead are available to you if you're using PostgreSQL, Redshift, or pretty much anything except MySQL
Let's see what this means in practice.
1) Who used it and what month they used it. To make things easier on ourselves later, lets represent the month as "number of months since 1970" so that we have a simple monotonically, increasing number.

2) For each row in #1, what is the next and previous month they used it, partitioned by user.

Ooooo!!!! Now we're getting somewhere!
3) For the results in 2, what's the difference between our current month and the next month. If it's one, then we know that the user came back the next month. If it's two or more, then we know there's a gap! That's a churn!

This table has everything we need to know!
4) Case statement the various possibilities. As an extra, we now have great insight into whether we are getting "revived" or "return" users.

5) There's some final cleanup and UNION of the two different data sets before we're done. You can see this in the complete query below. Basically we sometimes have >1 important row (ie the churn and the active) per row, so we double query our calculated table and union the results. But voila! We've got a single query for churn/active/return/new users.
Final Results after a quick Excel import and Pivot Table:
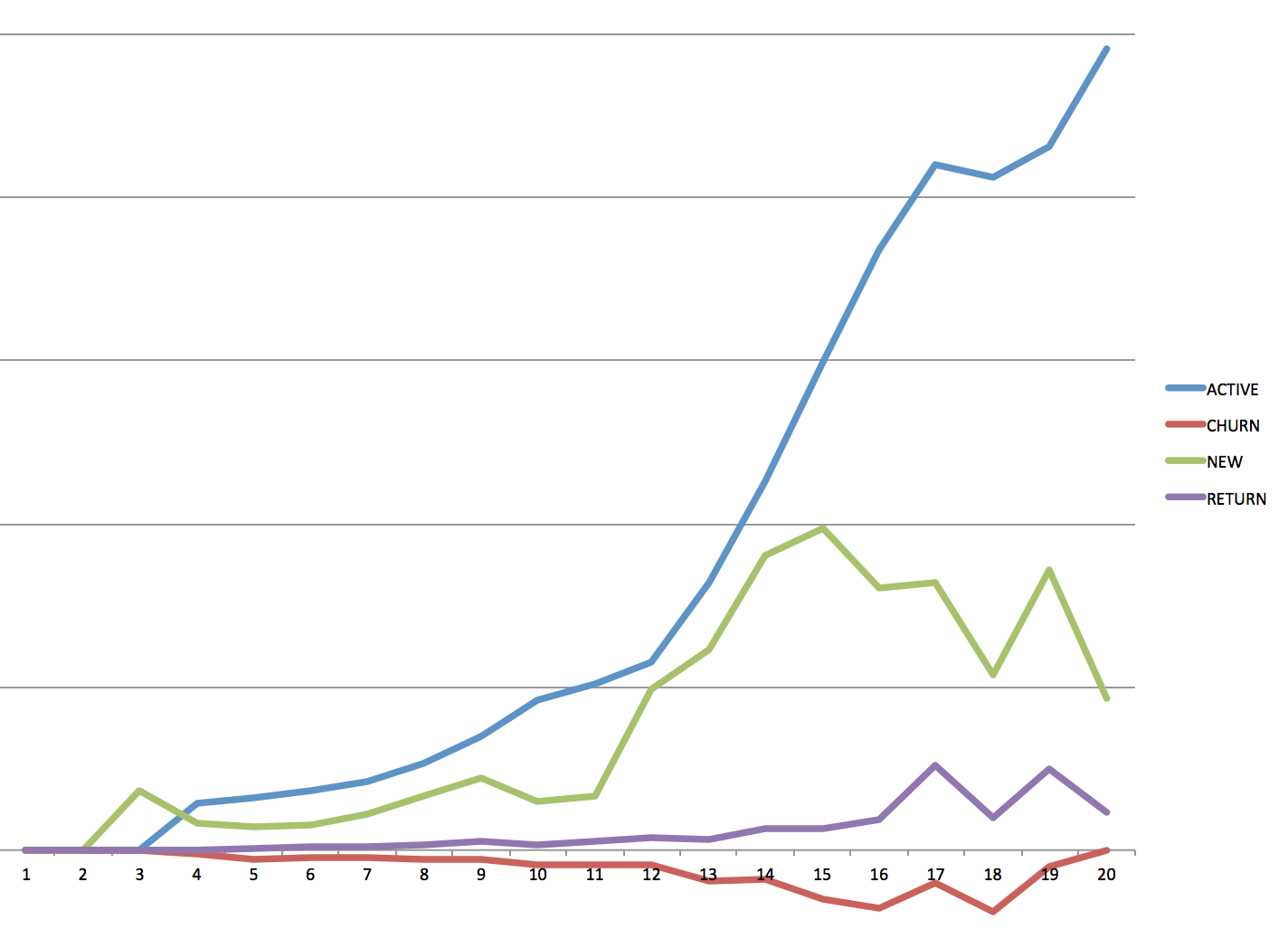
In summary, the above sql is a super useful way to get user activity data out of your database. Because it's a one stop query, it's really easy to add additionally filtering or grouping to this query, meaning you can easily segment these results.
ps Performance
Oh right, and how does it perform? Well on Redshift anyway cranking through 60Million rows takes about 7 seconds. In PostgreSQL I've haven't tried it on anything that large but it's never given me a problem.
Curious about what we do here at ForceRank? Give it a try!

